
Know about Dimensional Data Modelling for Big Data
- ScholarNest
- February 23, 2023
- Data Science and Analytics
Dimensional Data modelling has been a popular and effective approach for designing data warehouses and enabling business intelligence and analytics for many years. However, with the rise of big data, traditional dimensional modelling techniques face new challenges and limitations. Big data is characterized by its sheer volume, velocity, and variety, making it difficult to store, process, and analyze using traditional methods.
This article aims to provide an overview of dimensional Data modelling for big data, its challenges, strategies, and best practices. We will explore how big data differs from traditional data sources, the unique challenges of dimensional Data modelling for big data, and the techniques and technologies that can be used to overcome these challenges. We will also discuss the challenges and limitations of dimensional modeling for big data and real-world examples of how organizations have addressed them.
By the end of this article, readers will have a better understanding of how to design and implement effective dimensional models for big data and how to overcome the unique challenges that come with it.
What is Big Data?
Big data refers to large and complex data sets that cannot be quickly processed or analyzed using traditional data processing techniques. The size of big data sets can range from terabytes to petabytes, and they are often characterized by their high velocity, variety, and variability. Big data comes from various sources, including social media platforms, internet-of-things (IoT) devices, sensors, and other digital channels.

What is Dimensional data modeling?
Dimensional data modeling is a technique used in data warehousing and business intelligence (BI) to design a database schema that organizes data into easily understood and navigable structures. In dimensional modeling, data is organized into two types of tables: fact tables and dimension tables.
Fact Table
Fact tables contain the quantitative measures or metrics of the business, such as sales, revenue, or customer counts. These tables are typically large and contain numerical data that can be aggregated and analyzed. Fact tables are connected to dimension tables through foreign keys, which serve as the link between the two tables.
Dimension Tables
Dimension tables provide context to the measures in the fact table. They contain descriptive attributes that help to categorize and filter the data in the fact table. Examples of dimension tables include time, geography, customer, product, and salesperson. Dimension tables typically have fewer rows than fact tables and are often used to filter or group data during analysis.
Dimensional Data Modelling Techniques
Dimensional Data modelling is a denormalized approach to data modelling, which means that it is designed to optimize for query performance and ease of use rather than data storage efficiency. This approach simplifies data retrieval and analysis by making it easier to navigate through data relationships and quickly access relevant data.
The most popular dimensional Data modelling techniques include:
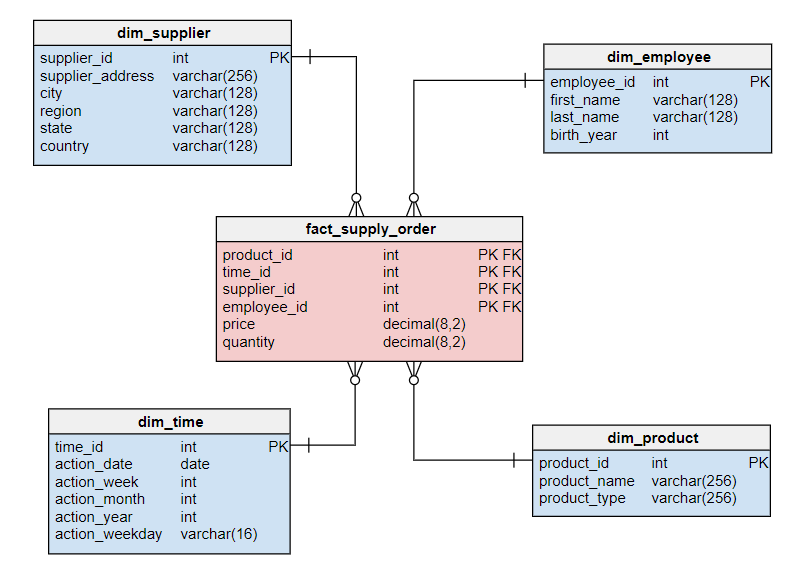
Star schema
In the star schema, the fact table is at the center of the schema, with dimension tables branching out from it. The star schema is simple and easy to understand, making it a popular choice for many data warehousing projects.
Snowflake schema
The snowflake schema is like the star schema but with additional levels of normalization. In the snowflake schema, dimension tables are further normalized into sub-dimension tables, resulting in a more complex schema that can be more difficult to understand and use but can be more space efficient.
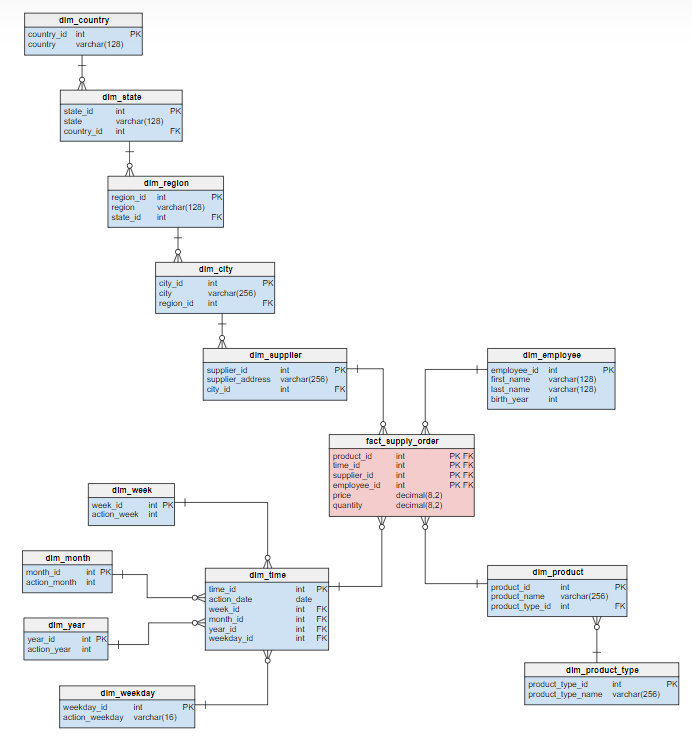
Overall, the choice of dimensional Data modelling technique depends on the specific needs of the data warehousing project and the trade-offs between simplicity, performance, and flexibility. The star schema is the most popular and widely used technique due to its simplicity and ease of use.
The benefits of dimensional data modelling
- Simplified data analysis: Dimensional Data modelling allows for easy navigation of large data sets, making it simpler for users to understand and analyze data.
- Improved query performance: Dimensional models are optimized for querying, with data stored in a structure that allows for efficient retrieval and aggregation of data.
- Flexibility: Dimensional models can easily accommodate changes in business requirements or data sources without requiring significant changes to the underlying data model.
- Ease of use: With its intuitive structure and simplified data relationships, dimensional data modelling is easier for non-technical users to understand and use, making it a popular choice for business intelligence and reporting applications.
Overall, dimensional data modelling is a powerful and flexible technique that enables efficient analysis and reporting of complex data sets, making it an essential tool for businesses looking to derive insights and value from their data.
The Implications of Big Data for Dimensional Modelling
Dimensional modeling has been widely used to design data warehouses and support business intelligence and analytics for many years. However, the rise of big data has brought new challenges and implications for dimensional modeling. Some of the critical implications include the following:
- Increased data complexity: big data sets are often characterized by their variety and variability, making it challenging to identify and define dimensions and hierarchies.
- Data ingestion challenges: Ingesting big data sets into a data warehouse can be challenging due to their size and complexity. Traditional extract-transform-load (ETL) processes may not be sufficient to handle big data sets, leading to longer processing times and potential data quality issues.
- Real-time processing requirements: big data sets often require real-time or near-real-time processing to enable quick decision-making and analysis.
- Cost considerations: Storing and processing big data sets can be expensive due to their size and complexity.
Technologies for Big Data
Despite the challenges, several technologies can be used to overcome the implications of big data for dimensional data modelling. These include:
- Hadoop and other distributed file systems: Hadoop and other distributed storage systems can store big data sets in a cost-effective and scalable manner. We can use Apache Hive and Apache Spark for large-scale data processing on the Hadoop platform.
- NoSQL databases: NoSQL databases such as Cassandra and MongoDB can store and query unstructured or semi-structured data.
- Cloud Data lakes: Cloud Data lakes can store and manage large and diverse data sets, providing a central repository for data storage. We can use Apache Spark-enabled distributed data processing engines such as Databricks, Google Data proc, and Amazon EMR.
- Cloud Data warehouse: Cloud-based data warehouses such as Amazon Redshift, Google Big Query, and Snowflake provide scalable and cost-effective solutions for storing and processing big data sets.
Challenges of Dimensional Data Modelling for Big Data
In this section, we will explore the challenges and limitations of dimensional Data modelling for big data in more detail.
Handling Complex Data Structures
Big data sets are often characterized by complexity, making it challenging to identify and define dimensions and hierarchies. In dimensional Data modelling, data is organized into facts and dimensions. Facts are the measurable data points, such as sales, revenue, or clicks, while dimensions are the attributes that provide context to the facts, such as time, product, or location. However, with big data, identifying relevant dimensions and hierarchies can be difficult due to the variety and variability of the data.
Data Ingestion and Integration
Another challenge in dimensional Data modelling for big data is data ingestion and integration. Traditional ETL processes may not be sufficient to handle big data sets, leading to longer processing times and potential data quality issues. In addition, big data sets may come from various sources and formats, requiring additional pre-processing and integration efforts.
Scalability and Performance
Scalability and performance are also significant challenges in dimensional Data modelling for big data. Storing and processing big data sets can be expensive due to their size and complexity. To address this challenge, distributed file systems such as Hadoop can be used to store, and Spark for processing big data sets in a cost-effective and scalable manner. However, this requires a different approach to designing and implementing dimensional models.
Real-time Processing and Analysis
Big data sets often require real-time processing and analysis to enable quick decision-making and analysis. However, traditional dimensional modeling techniques may not be suitable for real-time processing. In-memory processing and streaming technologies such as Apache Kafka and Spark Structured streaming can enable real-time processing and analysis of big data sets.
Data Governance and Security
Finally, data governance and security are critical considerations in dimensional modeling for big data. Big data sets may contain sensitive and confidential information, requiring additional security and access controls. In addition, data governance policies and procedures must be established to ensure the data’s accuracy, consistency, and integrity.
Strategies for Dimensional Modelling for Big Data
In this section, we will explore the strategies and best practices for designing dimensional models for big data, considering above discussed challenges and limitations.
Start with a Comprehensive Data Analysis
To design an effective dimensional model for big data, it’s essential to start with comprehensive data analysis. This involves understanding the structure and characteristics of the data, identifying relevant dimensions and hierarchies, and determining the relationships between them. This analysis should also consider the different data sources and formats and the data quality issues that may arise.
Embrace Flexible and Dynamic Dimensional Models
Traditional dimensional modeling techniques may not be suitable for big data due to the complexity and variability of the data. Instead, embracing more flexible and dynamic dimensional models that can adapt to changing data structures and requirements is essential. One approach is to use a hybrid model that combines the strengths of both dimensional and relational modeling techniques.
Leverage Scalable storage and In-Memory Processing.
To address scalability and performance challenges, leveraging scalable storage systems such as Cloud storage buckets to store big data and flexible computing engines such as Spark for efficient processing is essential. In-memory processing techniques such as Kafka and Spark streaming can also improve processing speed and reduce latency, enabling real-time or near-real-time analysis.
Use Agile and Iterative Development Processes
Agile and iterative development processes are ideal for designing dimensional models for big data. This involves working in small sprints to design, develop, and test the model, making incremental changes as needed. This approach enables teams to be more flexible and responsive to changing data structures and requirements, reducing the risk of project delays and failures.
Implement Strong Data Governance and Security Measures
Finally, strong data governance and security measures must be implemented to ensure the data’s accuracy, consistency, and integrity. This involves establishing data quality standards, implementing access controls and data protection mechanisms, and monitoring data used to detect and prevent security breaches.
Tools and Technologies for Dimensional Data Modelling for Big Data
In this section, we will explore the tools and technologies available for implementing dimensional models for big data, along with their benefits and limitations.
Apache Hadoop
Apache Hadoop is an open-source framework that enables distributed storage and processing of large data sets across clusters of commodity servers. Hadoop’s HDFS (Hadoop Distributed File System) provides a scalable and fault-tolerant storage solution, while its MapReduce programming model enables distributed processing of big data sets.
Hadoop’s ecosystem also includes various tools and technologies that support dimensional modelling, such as Apache Hive and Apache Spark. Hive is a data warehouse infrastructure that provides SQL-like querying capabilities for Hadoop. At the same time, Spark is a high-level platform offering SQL and Dataframe API to create programs for processing large data sets.
Spark and Databricks
Apache Spark is another open-source framework that provides distributed processing of big data sets. Spark’s in-memory processing engine allows it to perform batch processing, stream processing, machine learning, and graph processing tasks faster than Hadoop’s MapReduce.
Spark’s ecosystem includes tools such as Apache Spark SQL and Apache Spark Streaming, which can be used for dimensional modeling. Spark SQL provides a SQL interface to Spark, allowing data analysts to query data stored in Spark using SQL syntax. Spark Streaming enables real-time processing of data streams, making it ideal for processing and analyzing real-time data.
Databricks offers a variety of tools integrated with Apache Spark in its cloud-based platform. Databricks delta lake and Unity Catalog are essential tools for handling Big Data governance and data security at a large scale. Databricks offers built-in support for implementing Medallion Architecture that helps implement dimensional data modeling for batch streaming systems. It also provides a range of querying and reporting tools that enable data analysts to extract insights from large data sets.

Cloud-Based Data Warehouses
Cloud-based data warehouses such as Amazon Redshift, Google Big Query, and Snowflake provide scalable and cost-effective solutions for storing and processing big data sets. These cloud-based solutions offer built-in support for dimensional modeling and provide a range of querying and reporting tools that enable data analysts to extract insights from large data sets.
NoSQL Databases
NoSQL databases such as MongoDB, Cassandra, and HBase are designed for handling unstructured or semi-structured data, making them ideal for big data applications. These databases support flexible data modeling and provide fast read and write operations, enabling real-time analysis of large data sets.
Data Integration and ETL Tools
Data integration and ETL (Extract, Transform, Load) tools such as Apache NiFi, Azure Data Factory, and Talend provide the ability to extract data from multiple sources, transform it, and load it into a dimensional model. These tools enable data analysts to automate the data integration and ETL processes, reducing the risk of errors and improving the efficiency of the overall process.
Conclusion
Dimensional Data modelling is critical to designing a robust and effective big data solution. It enables organizations to make sense of their data and unlock valuable insights that can drive business growth and innovation.
Throughout this article, we have discussed various strategies and challenges related to dimensional modeling for big data. We have seen that while traditional dimensional modeling techniques still hold relevance, there are several unique challenges associated with big data that require careful consideration.
By following the best practices and strategies discussed in this blog post, organizations can effectively model their big data and gain valuable insights to stay ahead of their competition. However, it is essential to remember that there is no one-size-fits-all solution, and each organization’s needs and requirements are unique.
To conclude, dimensional modeling is crucial for data engineers and architects working with big data. By leveraging the best practices and techniques outlined in this article, organizations can effectively model their data, gain valuable insights, and achieve their business goals.


{kind=link}